Autore: by Antonello Camilotto
•
11 dicembre 2025
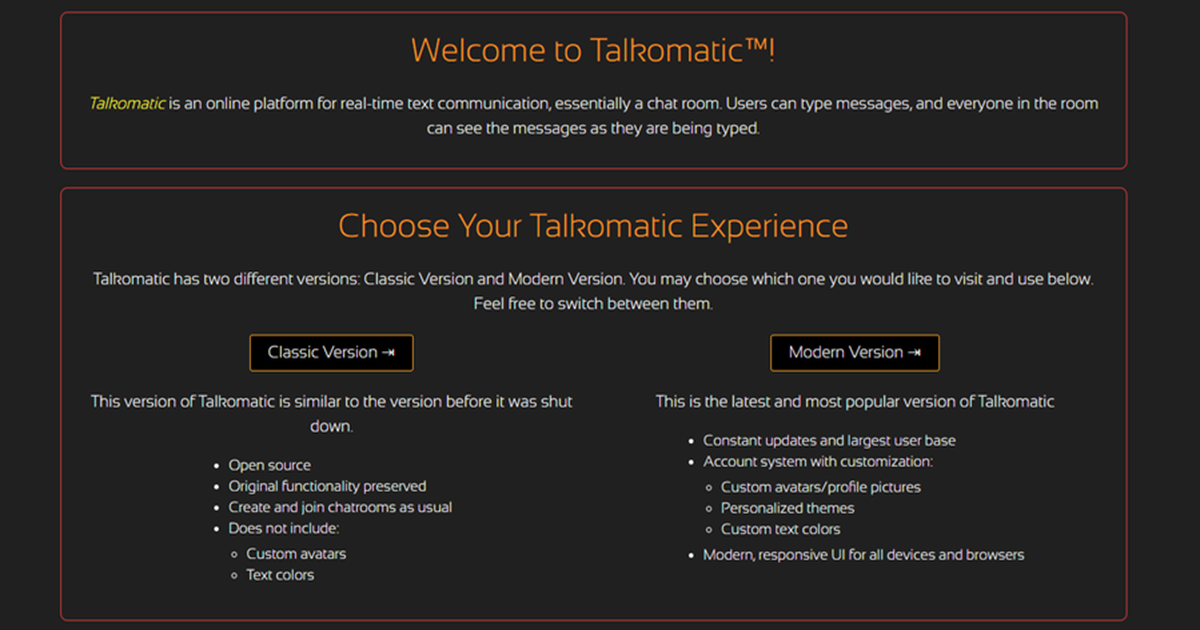
Quando oggi pensiamo alla messaggistica istantanea, ci vengono in mente WhatsApp, Telegram, Messenger o Signal. Ma l’idea di comunicare in tempo reale tramite una rete di computer è molto più antica di quanto si possa immaginare. Prima degli smartphone, prima di Internet, e persino prima dei PC come li conosciamo oggi, qualcuno aveva già inventato la chat istantanea. Era il 1973. E quello strumento si chiamava Talkomatic. Le origini: PLATO e la nascita di un’idea rivoluzionaria Talkomatic nasce all’interno del progetto PLATO (Programmed Logic for Automatic Teaching Operations), un sistema educativo computerizzato sviluppato presso l’Università dell’Illinois. PLATO è ricordato per molte innovazioni pionieristiche: display al plasma, giochi multiplayer, forum, email e, appunto, la chat in tempo reale. Nel 1973 gli sviluppatori Doug Brown e David R. Woolley crearono Talkomatic, una piattaforma di comunicazione dove più utenti potevano entrare in "canali" tematici e digitare messaggi che comparivano sullo schermo degli altri lettera per lettera, in tempo reale. A differenza delle chat moderne, dove il messaggio viene inviato solo quando si preme “Invio”, con Talkomatic gli utenti vedevano ciò che gli altri scrivevano istantaneamente, carattere dopo carattere. Un’esperienza di comunicazione sorprendentemente “dal vivo”, quasi paragonabile a una conversazione vocale. Un successo inatteso In poco tempo Talkomatic divenne una delle funzioni più popolari dell’intero sistema PLATO. Venne usato dagli studenti, dagli insegnanti e persino dai tecnici che lavoravano sui server. Nonostante le limitazioni tecnologiche dell’epoca — computer costosissimi, accesso remoto tramite linee telefoniche lente — il bisogno umano di comunicare in modo immediato trovò spazio in questa innovazione. La lenta scomparsa e la rinascita Con la fine del progetto PLATO e l’arrivo dei nuovi sistemi informatici, Talkomatic scomparve gradualmente. Ma la sua eredità continuò a vivere, influenzando le prime chat IRC, i messenger degli anni ’90 e, più in generale, l’intero concetto di messaggistica istantanea moderna. Nel 2014, uno dei suoi creatori, David R. Woolley, decise di riportarlo in vita online, ricreando una versione accessibile via web basata sul funzionamento originale: stanze di chat pubbliche, messaggi che scorrono lettera per lettera, interfaccia minimalista e un sapore fortemente retro. Perché oggi ha ancora un fascino particolare Oggi Talkomatic sopravvive come una sorta di museo vivente di Internet. È un pezzo di storia interattiva, che permette di fare un salto nel passato e provare cosa significasse comunicare ai primissimi giorni delle reti digitali. Il fascino di Talkomatic risiede proprio nella sua semplicità: nessuna criptazione o sticker animati; nessuna registrazione o profilo; solo utenti che digitano e vedono digitare gli altri. È un’esperienza che, paradossalmente, appare più “umana” di molte forme di comunicazione moderne. Un’eredità che continua Parlare di Talkomatic significa raccontare la nascita di una delle funzioni più utilizzate al mondo: la chat. Oggi decine di miliardi di messaggi vengono scambiati ogni giorno, ma tutto è iniziato da un esperimento universitario, un terminale al plasma e la visione di due programmatori. A 52 anni dalla sua creazione, Talkomatic non è solo un cimelio tecnologico: è un promemoria di quanto la necessità di comunicare sia alla base di ogni evoluzione digitale.